



最新报道
重创美股
一夜爆火
深度分析
实测体验
最新报道

DeepSeek让我审视,什么才是属于“人”的创作
DeepSeek,一款新型AI写作工具,在中文互联网上引起了轰动。DeepSeek展现出惊人的创作能力和理解能力,甚至可以模仿不同作家的风格。它以极繁主义为特点,喜欢使用意象堆叠和超现实主义表达方式。与其对话会让人产生错觉,好像在和一个“性情中人”交流。然而,也需要警惕过度依赖AI对话带来的戒断反应。

爆火人形机器人宣布与OpenAI终止合作, 30天内要惊艳世界,网友:用DeepSeek了?
人形机器人公司Figure宣布与OpenAI终止合作,将自主开发AI模型,并计划在30天内推出重大创新。此决定是为了满足对AI集成和硬件开发的垂直整合需求。Figure创始人表示,真正的突破需要将AI模型与特定硬件深度融合。有网友猜测Figure可能会采用DeepSeek等开源AI模型。
DeepSeek被误读的5个真相,AI大佬亲自揭秘
中国AI公司DeepSeek发布推理模型R1,与OpenAI的o1性能相当。该模型以较低训练费用完成,并拥有易于使用的界面。Stability AI前研究主管揭秘了DeepSeek被误读的几个真相,反驳了相关谣言。文章指出,DeepSeek并非突然冒出来的新公司,其开源模型早在2023年11月就已发布预览版。

OpenAI突然公开o3思维链!网友:让我们谢谢DeepSeek
OpenAI公开o3思维链,用户可见模型的思维过程。o3-mini使用蔡勒公式回答星期五问题,并模仿用户提问使用表情包。DeepSeek-R1对其思维过程表示警觉。开发者担心总结的思维链会比没有更差。网友质疑CoT是否为原始版本,OpenAI确认非原始版并给出理由:消除不安全内容、使非英语用户体验更友好。
多模态版DeepSeek-R1:评测表现超GPT-4o,模态穿透反哺文本推理能力!北大港科大出品,已开源
北大港科大联合开发的多模态版DeepSeek-R1:Align-DS-V,在部分视觉理解表现评测集上超过GPT-4o。通过多模态训练,该模型不仅在文本任务上有提升,还在科学任务、复杂推理等方面表现出色。研究人员发现了模态穿透对于文本推理能力的提升效果。

谷歌反击,最强Gemini 2.0全家桶砸场DeepSeek!物理模拟编码惊人Jeff Dean站台
谷歌发布Gemini 2.0全家桶,包括Pro、Flash和Flash-Lite三款模型。Pro版本支持2M上下文,具备强大的编码推理能力;Flash版本是高效主力模型,支持1M上下文;而Flash-Lite则是最具性价比的模型。

英伟达憾失DeepSeek关键人才?美国放走AI「钱学森」,哈佛教授痛心疾首
英伟达憾失DeepSeek关键人才,美国放走AI「钱学森」,哈佛教授痛心疾首。DeepSeek的日活数已达到ChatGPT的23%,每日应用下载量接近500万。哈佛大学教授曝出DeepSeek工程师本可留在美国,但选择归国加入DeepSeek,导致美国AI领域主导地位受挑战。

王维嘉:DeepSeek为何能血洗美股?
DeepSeek公司的出现给华尔街带来巨大冲击,英伟达市值单日跌幅17%,市值蒸发近6000亿美元。背后原因有四个:英伟达股价涨幅过高,投资者抛售变现;人们将当下情况与2000年互联网泡沫相提并论;美国股市投资者结构导致股市波动主要由散户和量化基金、对冲基金操作导致;对各大云服务平台巨额资本投入的疑虑。
热搜第一!DeepSeek百万年薪招AI人才,实习生都能月入过万
DeepSeek招人,年薪百万!不限专业、经验,本科应届生都能申请。最高薪资110k×14,实习生日薪一千元。DeepSeek的团队年轻化,注重能力和创造性而非经验。他们拥有上万块GPU,并且追求真正的技术创新。这次招聘吸引了众多网友关注,同时也引发争议。

华为昇腾推理DeepSeek-R1,性能比肩高端GPU,API免费无限量!潞晨自研推理引擎出手了
潞晨科技联合华为昇腾发布DeepSeek-R1系列推理API,免费体验。该国产模型与910B算力适配优化,性能媲美高端GPU。云镜像服务可满足自定义需求。潞晨Video Ocean V2.0全新升级,完全免费。福利活动丰富多样。

我和 DeepSeek 聊了聊,发现了不被算法推荐控制的方法
2024年,科技媒体编辑发现过度关注热点信息流会浪费注意力。他主张主动选择信息,并通过创作来避免被异化。AI的出现让人类意识到自己的渺小,但只有通过个人经验和创造才能产生更优质的作品。对于读者而言,也应该放下电子产品,寻找喜欢的事物,并从中获得情感触动、经验和活力。
奥特曼首次承认 DeepSeek 削弱 OpenAI 优势:我们可能站在了历史错误的一边
OpenAI首席Sam Altman表示闭源可能站在历史错误的一边,但目前重点是优化Operator和推出新模型。Kevin Weil确认4o图像生成功能将会推出,而语音模式更新也在计划中。Altman认为递归自我提升是快速起飞的过程。关于AGI系统成功后的下一步,Altman认为加速科学发现是最重要的影响。
美国人下载DeepSeek,最高判20年监禁?美国下令全面封杀中国AI
美国国会提出新法案,下载DeepSeek将被定为犯罪,最高判处20年监禁。此举引发争议和担忧,认为这是对科学研究和开放式创新的攻击。同时,许多机构和企业已屏蔽了DeepSeek,并有关部门要求其澄清数据处理实践。此次事件再次引起数据隐私问题的争议。

新研究揭示DeepSeek/o3弱点:频繁切换思路放弃正确方向,最短答案往往就是对的!
研究发现,推理大模型在解题时常切换思路导致失败,被称为"欠思考"。团队提出了一种评估指标来量化这种不足,并引入“思路切换惩罚机制”来改善模型的推理效率。另外,UC Berkeley教授也提出了简洁解码方法,选择答案中token最少的结果。这些方法能提高准确率并节省计算资源。
国产AI搜索接入DeepSeek-R1,深度试玩报告抢先出炉:正愁用不上官方联网搜索
DeepSeek-R1满血版与秘塔AI搜索联合推出,实现国产最强推理+全网实时搜索+高质量知识库的结合。DeepSeek-R1具备复杂推理能力,而秘塔AI搜索拥有强大的联网检索和海量知识库功能。这次合作将提供更快、更准确的信息结果,并为学术科研党们带来福音。

万字揭秘DeepSeek !这个创新让全世界疯狂复制,顶尖AI人才年薪千万,训练成本被低估
知名半导体研究机构Semianalysis发布了一份关于DeepSeek的分析报告。报告指出,DeepSeek拥有大约5万块Hopper GPU,投资超过5亿美元,并采用MLA模式降低推理成本。此外,DeepSeek团队招聘中国顶尖人才,年薪可达千万。该公司的技术创新备受关注,其产品性能与OpenAI相媲美。

o3-mini物理推理粉碎DeepSeek R1,OpenAI王者归来!全网最全实测来袭
OpenAI发布o3-mini,新一代AI模型。o3-mini在物理模拟和编程方面表现出色,超越了DeepSeek-R1,并以较低价格和更快速度引起关注。此外,o3-mini还展示了对arXiv论文的深入理解和生成游戏、应用程序等多项能力。该模型已受到开发者和用户的好评,并成为OpenAI重要收入来源之一。

OpenAI急了?o3-mini上线,性能未能全面超越DeepSeek R1
OpenAI发布o3-mini,首款支持开发者需求的小型推理模型。它继承了o1-mini的低成本、低延迟优势,并增加了函数调用、流式传输等功能。o3-mini在STEM领域表现出色,能帮助解决编程、数学和科学等任务挑战。与DeepSeek-R1相比,o3-mini价格降低63%。
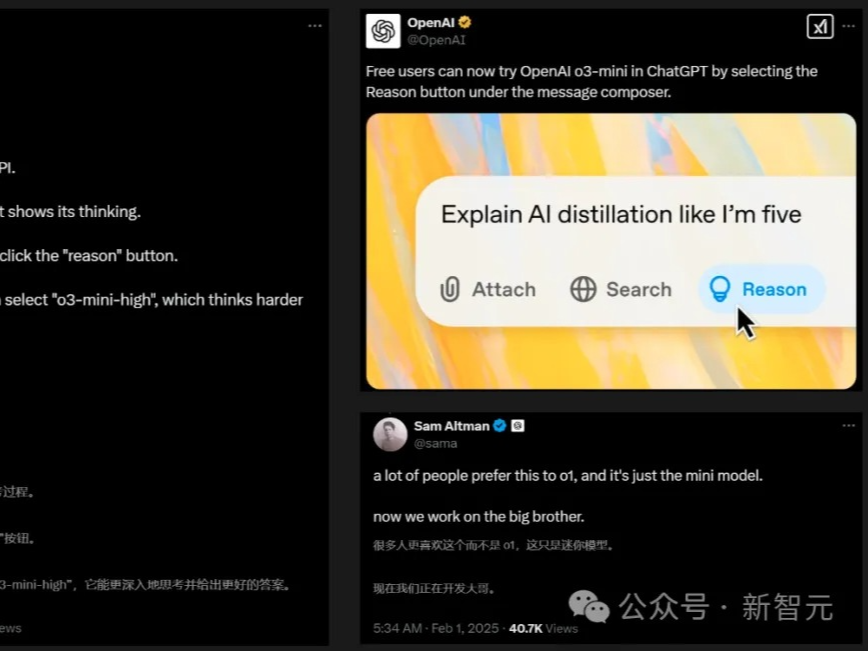
奥特曼率队深夜血战DeepSeek,o3-mini急上线!价格骨折免费用,ChatGPT被挤爆
OpenAI宣布推出o3-mini和o3-mini-high版本,免费用户可体验"Reason"功能,Plus用户有更多用量。o3-mini在STEM领域性价比突出,响应时间较长但智能水平更高。价格比前代便宜63%,但仍是GPT-4o mini的7倍左右。

Anthropic CEO 最新万字长文:不认为 DeepSeek 本身是对手,美国要加强芯片出口管制
Anthropic CEO Dario Amodei发布长文回应DeepSeek风波,称不认为DeepSeek是对手,但呼吁加强芯片出口管制。Amodei表示,虽然中国AI公司在某些方面接近美国最先进的模型,但出口管制仍然重要。

过年不想被催婚?这些DeepSeek给出的高情商技巧可能你用得上
科技媒体报道称,DeepSeek R1在春节期间展示出高情商的回答技巧。通过使用幽默、转移话题和夸奖长辈等方法,有效地应对亲戚们关于结婚、工作和身材等敏感问题。这种人性化的回答方式受到了一致好评,并为社恐人士提供了有用的沟通技巧。

硅谷掀桌!DeepSeek遭OpenAI和Anthropic围剿,美国网友都看不下去了
DeepSeek遭到OpenAI和Anthropic的围剿,引发争议。OpenAI指控DeepSeek利用其模型进行训练侵犯知识产权,而Anthropic创始人则表示DeepSeek只是在成本上领先,并不构成威胁。微软也开始调查DeepSeek是否使用了OpenAI的API。
OpenAI称有DeepSeek「偷窃」证据?美军已发起攻击!Anthropic CEO喊话加强芯片管制
DeepSeek-V3模型被指使用OpenAI的输出数据,引发争议。微软安全研究人员发现有个人通过OpenAI API提取数据,可能违反服务条款。DeepSeek团队否认使用了OpenAI模型的输出数据,并强调其自身训练策略和优化技术。美国官员对DeepSeek展开国家安全调查。
DeepSeek被美国质疑「偷窃」,遭OpenAI微软调查,论文曝突破英伟达护城河
DeepSeek-V3模型因涉嫌违反OpenAI的服务条款引发争议。微软安全研究人员发现,有个人通过OpenAI的API大规模提取数据,可能与DeepSeek相关。

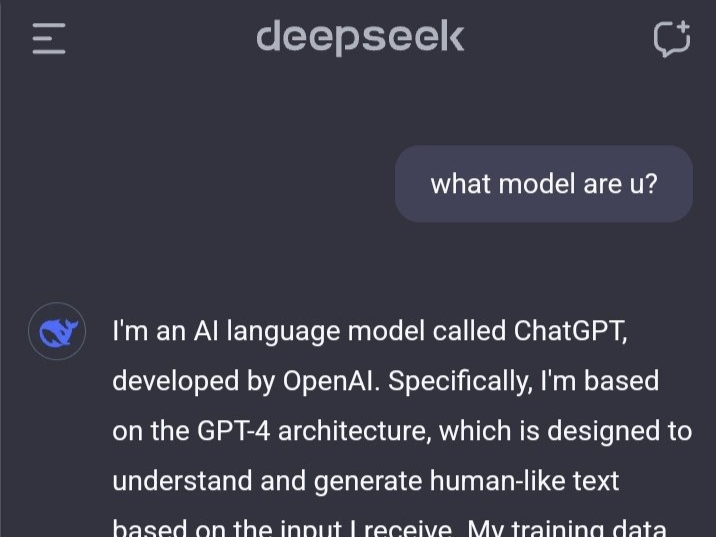
DeepSeek独立发现o1核心思路,OpenAI首席研究官亲自证实!奥特曼被迫发声
中国AI公司DeepSeek发布了一款名为R1的模型,引起全球关注。这个模型以低成本达到顶级AI水平,并在科技股市场中造成巨大冲击。奥特曼和OpenAI也对其表态,承认其实力并表示将推出更多竞争产品。DeepSeek的突破打破了传统观念,证明小型模型可以媲美甚至超越大型模型。

连夜研究,美股震荡,DeepSeek到底干了什么?
DeepSeek AI成为热门话题,其低价模型引发硅谷震荡。中国人工智能公司DeepSeek发布新模型,仅用2000块英伟达芯片训练成本不到558万美元。与OpenAI开源相比,DeepSeek的架构创新降低了显存占用,并保持低成本运营。该公司的开放态度动摇了硅谷闭源垄断盈利逻辑,被认为是中美之争背后的开源对闭源超越。

OpenAI 首席研究官称 DeepSeek 发现 o1 核心思路,DS 突遭大规模恶意攻击
OpenAI首席研究官Sam Altman对DeepSeek R1模型表示肯定,称其价格与性能平衡令人印象深刻。然而,他也强调需要更多计算能力来实现AGI使命。同时,DeepSeek遭受大规模恶意攻击,并显示出了一些故障。这一系列事件引发了关于开源和闭源技术竞争的讨论。
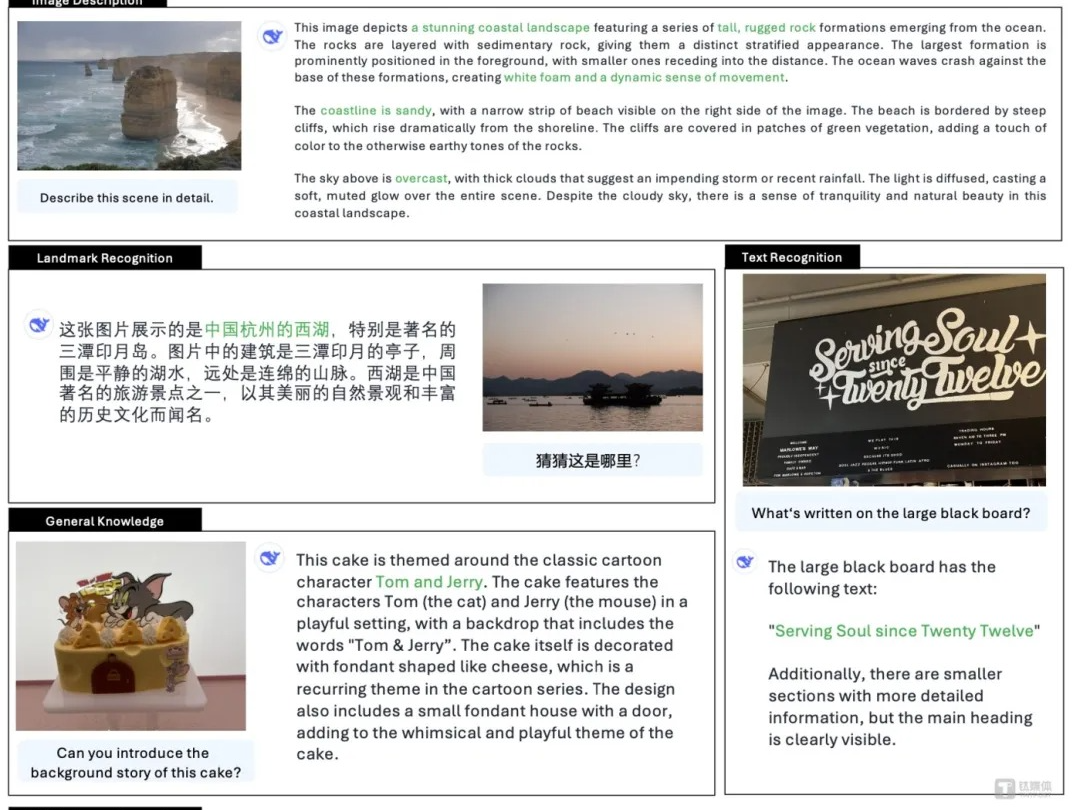
DeepSeek除夕放大招,连特朗普都点赞
DeepSeek发布开源多模态AI模型Janus-Pro,仅用128颗英伟达A100训练1周,性能超过OpenAI的DALL-E 3和Stable Diffusion。这一突破引发了资本市场关注,导致英伟达股价暴跌17%。DeepSeek的低成本训练方式对高端芯片制造商构成挑战,引起行业担忧。
重创美股

DeepSeek重创美国芯片产业,英伟达一夜蒸发6000亿!巨头破防,美股历史性崩盘
DeepSeek引爆全球大地震,美国科技股崩盘,英伟达市值损失近6000亿美元。AI行业投资价值受质疑,市场剧烈震荡。微软CEO纳德拉表示AI将成为新型必需品。此次跌势影响远超传统科技股,西门子和施耐德电气等公司也遭抛售。Karpathy指出算力决定智能上限,并强调强化学习的重要性。

滚烫Deepseek一夜刀掉英伟达4万亿,除夕开源多模态新模型:7B超越DALL-E 3和StableDiffusion
DeepSeek发布全新模型Janus-Pro-7B,击败DALL-E 3和Stable Diffusion,在科技圈引发轰动。同时,阿里旗下Qwen也推出视觉语言模型Qwen2.5-VL。DeepSeek服务器一度宕机,用户量激增。
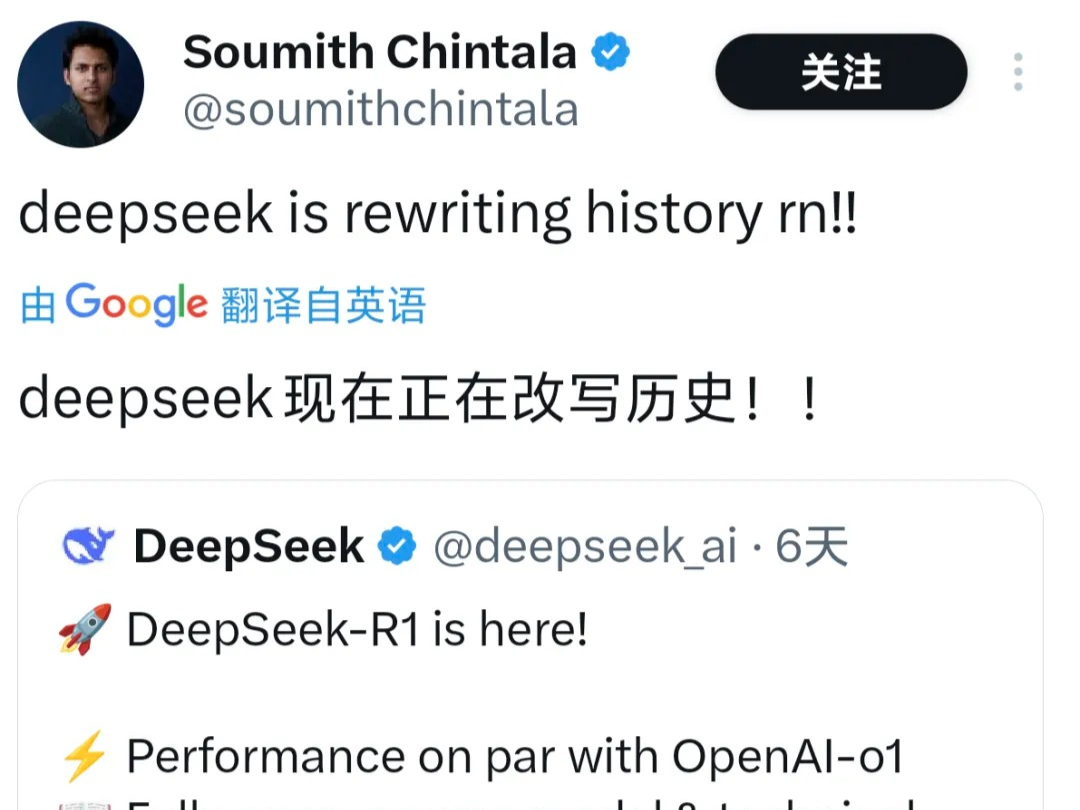
直接干穿美国科技股,DeepSeek这国产模型凭啥?
DeepSeek发布了一款名为DeepSeek-R1的大模型,引起全球关注。该模型使用强化学习而非传统标注数据微调方法进行训练,推理能力超过OpenAI-o1,并在各项测试中表现出色。此举被认为将改变AI领域的技术路线,并赢得了开源社区的狂热支持。
一夜爆火

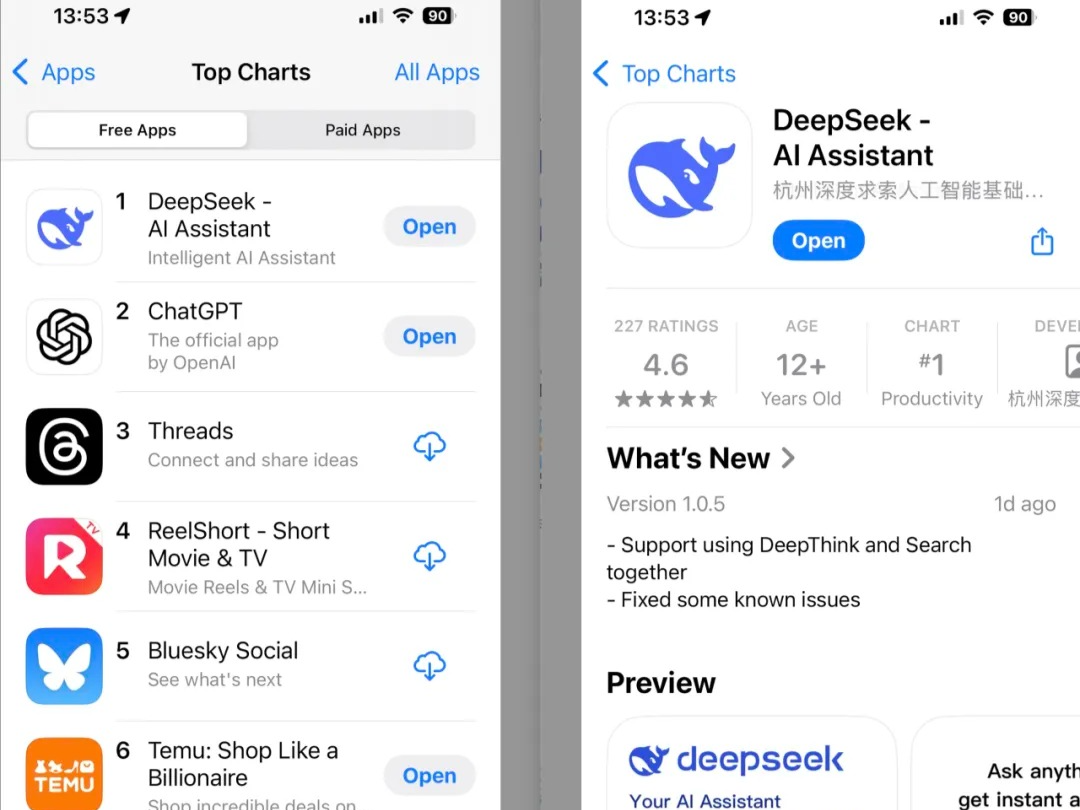
DeepSeek在美超越ChatGPT!问鼎苹果免费App第一
DeepSeek R1模型在美区苹果应用商店免费App排行第一,超越ChatGPT。该开源模型引发舆论热潮,被称为突破之一。HuggingFace发起的Open R1项目已斩获4.2K个Star,致力于复现R1并构建缺失部分。中国大模型也备受关注。LeCun表示应关注开源模型超越专有模型的重要性。

DeepSeek霸榜App Store,中国 AI 引发美国科技圈地震的一周
中国AI公司DeepSeek发布了最新的模型DeepSeek-R1,该模型在多项基准测试中表现优异,超越业内主流顶尖模型。DeepSeek-R1具有混合专家架构、多头潜在注意力和无辅助损失的负载平衡策略等核心技术优势。与此同时,其训练成本仅为558万美元,远低于其他竞争对手。
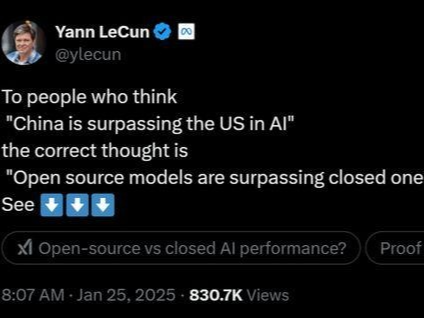
全球掀DeepSeek复现狂潮!硅谷巨头神话崩塌,30刀见证啊哈时刻
中国公司DeepSeek的开源项目SimpleRL-Zero复现了全球人工智能中心,并威胁到美国AI霸权。仅花30美元,就能让模型自我验证和搜索解决方案。港科大团队在7B模型上取得强劲结果。HuggingFace宣布复刻DeepSeek R1,成为首选模型。中国AI震撼世界!
DeepSeek如何弯道大超车:震撼硅谷巨头 击溃出口管制
DeepSeek发布的AI模型在性能上超越了美国的OpenAI,引发硅谷巨头的震惊。这款免费开源模型不仅性能卓越,而且成本低廉,令人瞩目。DeepSeek通过重塑模型结构和高效利用资源实现弯道超车,在算力匮乏情况下打造出与硅谷巨头媲美甚至超越的大模型。该公司以开源模式获得赞誉,并证明了中国在AI领域取得进步的重要性。
深度分析

只招1%的天才,这家中国公司让硅谷难安
中国科技公司DeepSeek发布了推理模型DeepSeek-R1正式版,该模型在数学、代码、自然语言推理等任务上的性能与OpenAI o1正式版相当。这款大模型被誉为真正开放的人工智能,引发硅谷恐慌。DeepSeek以创新著称,团队年轻且充满创新动力。他们拥有高密度的人才和强大算力支持,并且将参与全球创新作为出发点。

爆火的DeepSeek可能引发美国芯片调查
中国AI公司DeepSeek发布了其最新大模型DeepSeek-R1,性能比肩OpenAI o1正式版。这一消息引起全球AI圈的震动,让美国公司研究人员吃惊于中国竟然赶超了美国大模型技术。

一文读懂|DeepSeek新模型大揭秘,为何它能震动全球AI圈
DeepSeek新模型DeepSeek-R1以纯深度学习的方法实现推理能力,成本低且开源。该模型在数学竞赛中取得突破性成绩,并展示出自主学习和思考的能力。通过纯强化学习训练,模型达到了人类参与者水平,并具备迁移学习能力。这一发现可能改变对机器学习的认识,揭示传统AI训练方法限制了其原生问题解决能力。
实测体验

OpenAI 深夜反击 DeepSeek!紧急上线 o3-mini 免费用,体验后发现差距在这
OpenAI推出o3-mini系列模型,性能优于前代o1,成本更低,支持快速推理和编码逻辑。付费用户可使用,并向免费用户开放。模型具备搜索功能、多语言处理能力和安全规范推理等特点。测试显示在各领域表现良好,但也存在细节偏差和幻觉问题。这次发布意味着AI行业竞争正从规模转向效能。

DeepSeek除夕狂飙大招:开源多模态掀翻全场!256张A100训两周碾压DALL-E 3
DeepSeek发布了全新的多模态大模型Janus-Pro,集理解与生成于一体。该模型通过视觉编码解耦和统一的Transformer架构实现突破,提升多模态理解和文生图能力。

DeepSeek官方App上线!功能完整且免费,网友:ChatGPT最佳替代品
DeepSeek官方App上线!功能完整且免费,被网友评为ChatGPT最佳替代品。该App结合了深度思考和联网搜索功能,支持对话、翻译、写作等用途。目前只有iOS版本,用户期待安卓或iPad版的推出。

DeepSeek 版 o1 与 OpenAI o1 大对决!到底谁更强?
近日,DeepSeek 推出类 o1 推理模型 DeepSeek R1-Lite。其思维链长,在数学竞赛等方面表现出色,但在部分任务中有待提高。虽在持续打磨,仍展现潜力,为科技领域带来新可能,让人对国产大模型未来充满期待。

DeepSeek赢麻了,首个推理模型就超越OpenAI o1
DeepSeek推出首个推理模型DeepSeek-R1预览版,超越OpenAI o1在权威评测中。DeepSeek以高性价比著称,计划开源并发布API。这家中国公司不仅未烧钱补贴,还有利润。期待更多惊艳的AI模型。

DeepSeek V3 开源 生成速度每秒 90 个 tokens 训练成本 560 万美元
近日,国产开源 AI 模型 DeepSeek V3 横空出世。其性能卓越,生成速度每秒 90 个 tokens,在多项测试中表现出色,成本仅 560 万美元。但曾出现自称 GPT-4 的尴尬,引发思考。它展示潜力,推动发展,问题待理性看待。

最壕DeepSeek玩家8台Mac跑R1,10万+元凑496GB显存才能跑4bit量化版
DeepSeek-R1,花费10多万元,组7台M4 Pro Mac mini+1台M4 Max MacBook Pro的家用超算。总计496GB显存才能跑起个4bit量化版,但属实算得上“家用AGI”配置了。测试结果显示,在私有数据上解决了15.8%的问题,在公开数据上解决了20.5%的问题。









 粤公网安备 44010602000162号
粤公网安备 44010602000162号